1 Introduction
1.1 What is Applied Geodata Science?
Data science is interdisciplinary by nature. It sits at the intersection between domain expertise, Statistics and Mathematics knowledge, and coding skills. Data science generates new insights for applications in different fields by combining these three realms (Fig. Figure 1.1). Combining only two of the three realms falls short of what data science is (Conway, 2013).
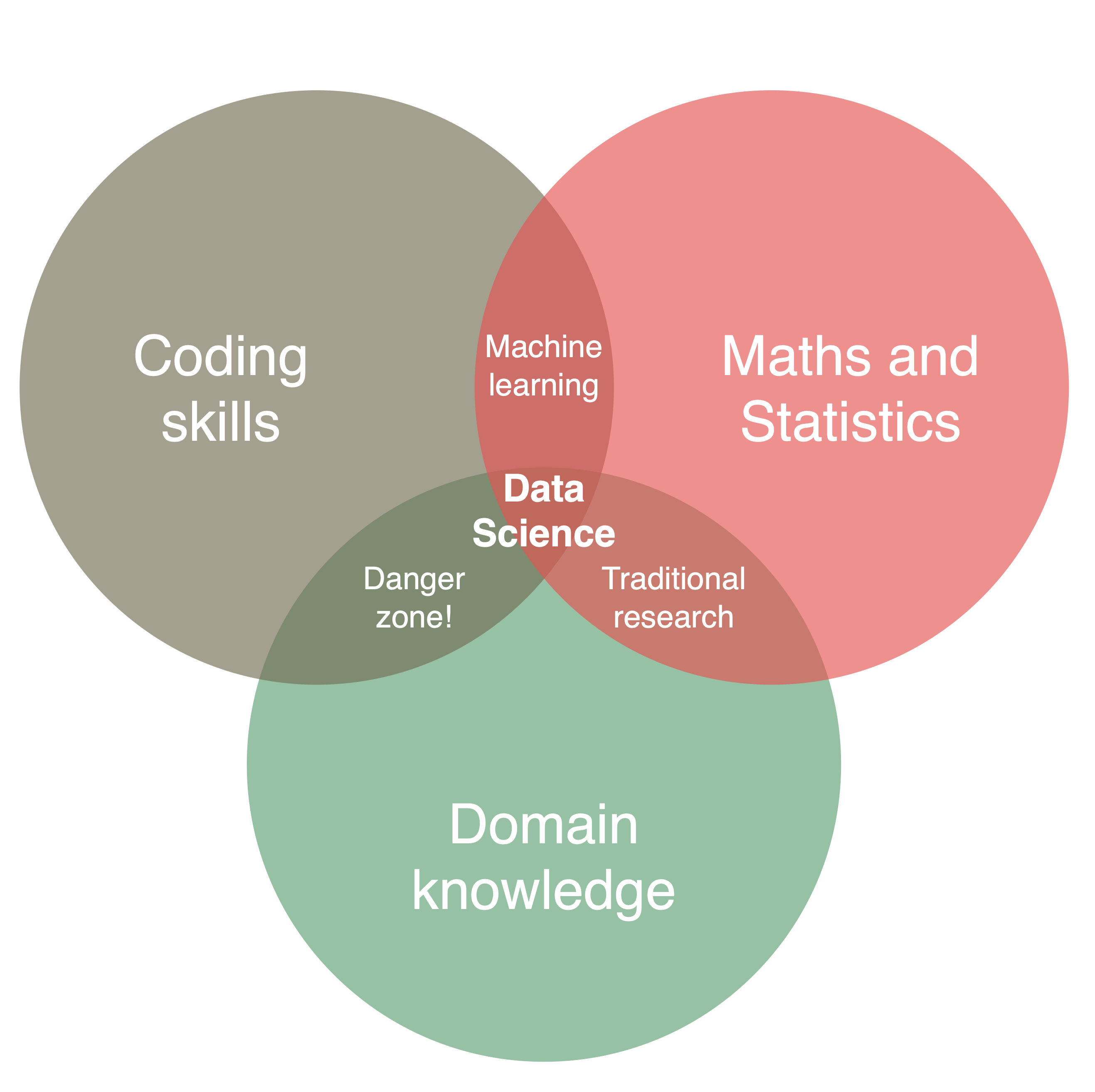
Dealing with data requires coding (but not a degree in computer science). Coding skills are essential for file and data manipulation and for thinking algorithmically.
Basic knowledge in Statistics and Mathematics are needed for extracting insights from data and for applying appropriate statistical methods. An overview of methods, a general familiarity, and an intuitive understanding of the basics are more important for most data science projects than having a PhD in Statistics.
Statistics plus data yields machine learning, but not “data science”. In data science, questions and hypotheses are motivated by the scientific endeavor in different domains or by applications in the public or private sectors. To emphasize the distinctively applied and domain-oriented approach to data science of this course, we call it Applied Geodata Science.
Of course, empirical research has always relied on data. The essential ingredient of a course in (Applied Geo-) data science is that it emphasizes the methodological aspects that are unique and critical for data-intensive research in Geography and Environmental Sciences, and for putting Open Science into practice.
This course is also supposed to teach you how to stay out of the “danger zone” - where data is handled and models are fitted with a blind eye to fundamental assumptions and relations. The aim of data science projects is to yield credible (“trustworthy”) and robust results.
1.2 The data science workflow
The red thread of this course is the data science workflow (Fig. Figure 1.2). Applied (geo-) data science projects typically start with research questions and hypotheses, and some data at hand, and (ideally) end with an answer to the research questions and the communication of results in textual, visual, and reproducible forms. What lies in between is not a linear process, but a cycle. One has to “understand” the data in order to identify appropriate analyses for answering the research questions. Before we’ve visualized the data, we don’t know how to transform it. And before we’ve modeled it, we don’t know the most appropriate visualization. In practice, we approach answers to our research questions gradually, through repeated cycles of exploratory data analysis - repeated cycles of transforming the data, visualizing it, and modelling relationships. More often than not, the exploratory data analysis generates insights about missing pieces in the data puzzle that we’re trying to solve. In such cases, the data collection and modelling task may have to be re-defined (dashed line in Fig. Figure 1.2), and the exploratory data analysis cycle re-initiated.
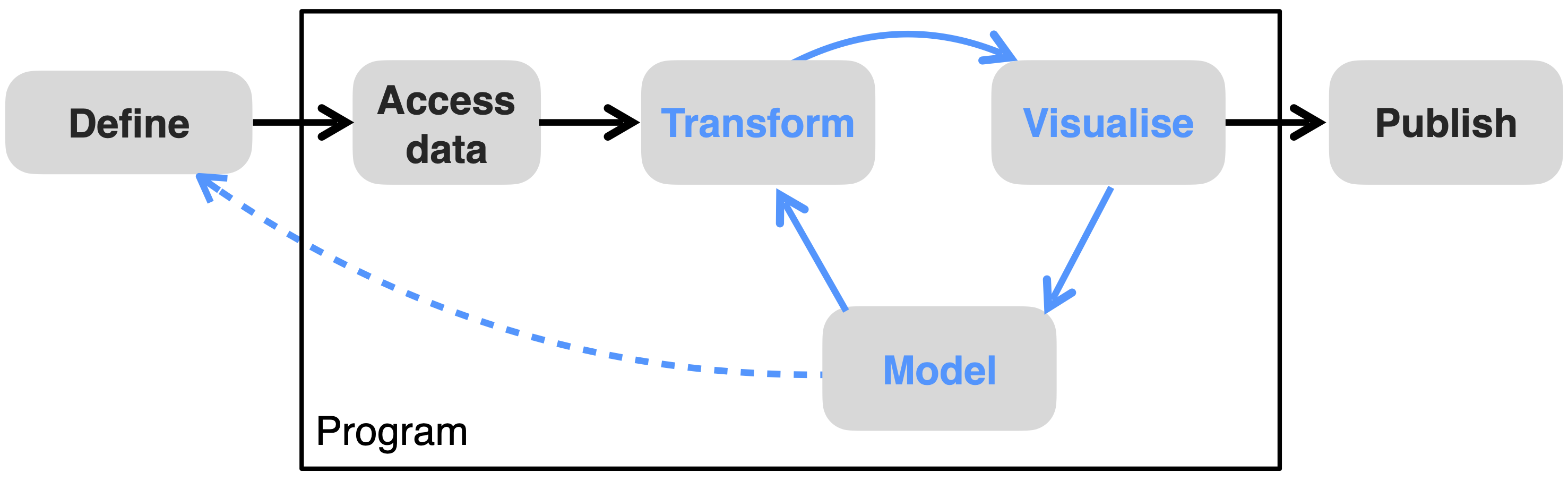
As we work our way through repeated cycles of exploratory data analysis, we take decisions based on our data analysis, modelling, and visualizations. And we write code. The final conclusions we draw, the answers to research questions we find, and the results we communicate rest on the combination of all steps of our data processing, analysis, and visualization. Simply put, it rests on the reproducibility (and legibility) of our code (encapsulated by ‘Program’ in Fig. Figure 1.2).
1.3 Why now?
Three general developments set the stage for this course. First, Geography and Environmental Sciences (as many other realms of today’s world) have entered a data-rich era (Chapters Chapter 6). Second, machine learning algorithms have revolutionized the way we can extract information from large volumes of data (this Chapter and Chapters Chapter 11 - Chapter 12). Third, Open Science principles (Chapter Chapter 5) - essential for inclusive research, boundless progress, and for diffusing science to society - are becoming a prerequisite for getting research funded and published. The skill set required to make use of the potentials of a data-rich world is diverse and is often not taught as part of the curriculum in the natural sciences (as of year 2023). This course fills this open space.
1.4 A new modelling paradigm
What is ‘modelling’? Models are an essential part of the scientific endeavor. They are used for describing the world, explaining observed phenomena, and for making predictions that can be tested with data. Models are thus a device for translating hypotheses of how the world operates into a form that can be confronted with how the world is observed.
Models can be more or less explicit and more or less quantitative. Models can come in the form of vague mental notions that underpin our view of the world and our interpretation of observations. Towards the more specific end of this spectrum, models can be visualizations. For example a visualization of how elements in a system are connected. At the arguably most explicit and quantitative end of the spectrum are models that rely on mathematical descriptions of how elements of a system are connected and how processes operate. Examples of such models include General Circulation Models of the climate system or models used for Numerical Weather Prediction. Such models are often referred to as mechanistic models.
A further distinction within mechanistic models can be made between dynamic models that describe a temporal evolution of a system (e.g., the dynamics of the atmosphere and the ocean in a General Circulation Model) and “static” models (e.g., a model for estimating the power generation of a solar photovoltaics station). In a dynamic model, we need to specify an initial state and the model (in many cases given additional inputs) predicts the evolution of the system from that. In a static model, the prediction can be described as a function of a set of inputs, without temporal dependencies between the inputs and the model prediction.
Often, mechanistic and empirical models (or, here used as synonym, statistical models) are distinguished. Empirical models can be viewed as somewhere closer towards the less explicit end of the spectrum described above. In mechanistic models, the mathematical descriptions of relationships are informed by theory or by independently determined relationships (e.g., laboratory measurements of metabolic rates of an enzyme). In contrast, empirical models rely on no, or only a very limited amount of a priori knowledge that is built into the model formulation. However, it should be noted that mechanistic models often also rely on empirical or statistical descriptions for individual components (e.g., the parametrisation of convection in a climate model), and statistical models may, in some cases, also be viewed as a representation of mechanisms that reflects our theoretical understanding. For example, depending on whether a relationship between two variables is linear or saturating by nature, we would chose a different structure of an empirical model. An specific example is the light use efficiency model (Monteith, 1972) that linearly relates vegetation productivity to the amount of absorbed solar radiation. It simply has the form of a bivariate linear regression model. Vice-versa, traditional statistical models also rely on assumptions regarding the data generating process(es) and the resulting distribution of the data.
Supervised machine learning models can be regarded as empirical models that are even more “assumption free” than traditional statistical models. In contrast to mechanistic models where rules and hypotheses are explicitly and mathematically encoded, and in contrast to statistical models where assumptions of the data distribution are made for specifying the model, machine learning approaches modelling from the flip side: from the data to the insight (Breiman, 2001). Rules are not encoded by a human, but discovered by the machine. Machine learning models learn from patterns in the data for making new predictions, rather than relying on theory and a priori knowledge of the system. In that sense, machine learning follows a new modelling paradigm. The learning aspect in machine learning refers to the automatic search process and the guidance of the model fitting by some feedback signal (loss function) that are employed in machine learning algorithms (see also Chapter Chapter 11).
The aspect of “patterns in the data” is key here. Often, these patterns are fuzzy. Rule-based algorithms have a limited capacity for dealing with such problems. Symbolic artificial intelligence is based on rules and underlies, for example, a computer playing chess (Chollet & Allaire, 2018). However, where rules cannot be encoded from the outset, symbolic artificial intelligence has reached its limits. A breakthrough in learning from fuzzy patterns in the data has been enabled by deep learning. Through multiple layers of abstraction of the data, deep learning models identify underlying, abstract, relationships and use them for prediction. Deep learning has been extremely successful in solving problems, e.g., in image classification, speech recognition, or language translation.
However, the abstraction comes at the cost of interpretability. Deep learning models and machine learning models in general are used with an emphasis on prediction and have seen particularly wide adoption in fields where a false prediction has acceptable consequences (An inappropriate book recommendation based on your previous purchases is not grave.) (Knüsel et al., 2019). The model itself remains a black box and its utility for hypothesis testing is limited. This challenge has spurred the field of interpretable machine learning, where solutions are sought for uncovering the black box and probe the model for its trustworthiness.
Chapters Chapter 9 up to Chapter 12 lead into the world of machine learning and introduce the essential steps of the modelling workflow without delving into deep learning. Together with its preceeding chapters, this completes the toolbox required for making the first data scientific steps for applications in Geography and Environmental Sciences. This may be only just the beginning…
1.5 Reading and link collection
Foundations
Leo Breiman: Statistical Modeling: The Two Cultures (with comments and a rejoinder by the author).” Statist. Sci. 16 (3) 199 - 231, 2001. https://doi.org/10.1214/ss/1009213726
- A paper describing the paradigm shift in statistical modelling - from traditional approaches to machine learning. Written in accessible language by the inventor of the Random Forest algorithm.
Marquet, P. A., Allen, A. P., Brown, J. H., Dunne, J. A., Enquist, B. J., Gillooly, J. F., Gowaty, P. A., Green, J. L., Harte, J., Hubbell, S. P., O’Dwyer, J., Okie, J. G., Ostling, A., Ritchie, M., Storch, D., & West, G. B.: On Theory in Ecology. BioScience, 64(8), 701–710, 2014. https://doi.org/10.1093/biosci/biu098
- A key statement of this paper summarises its content: “Some have suggested that theories are irrelevant in the big data era—that correlations are sufficient to build a vigorous science […]. We disagree.”
Open Science
https://book.the-turing-way.org/
- A collaboratively developed resource (website, book) that explains the motivation and introduces the principles and key definitions of Open Science.
Data wrangling
Hadley Wickham and Garrett Grolemund: “R for Data Science”, https://r4ds.had.co.nz/
Max Kuhn and Kjell Johnson: “Feature Engineering and Selection: A Practical Approach for Predictive Models”, http://www.feat.engineering/
- A practical guide to all steps of the data science workflow, with particularly valuable chapters on data wrangling and feature engineering. This free online book is not accompanied by code and is thus useful for any data science practitioner, irrespective of their preferred programming language.
Data visualisation
Claus O. Wilke: “Fundamentals of Data Visualization”, https://clauswilke.com/dataviz/
- A comprehensive resource for data visualisation - not specific to any programming language, but specific about the grammar of graphics. Covers concepts of Chapter Chapter 8 - but in more depth. The go-to resource for the implementation of data visualisation using the {ggplot2} R library is Wickham and Grolemund (see above).
Crameri, F., Shephard, G.E. & Heron, P.J. The misuse of colour in science communication. Nature Communications 11, 5444 (2020). https://doi.org/10.1038/s41467-020-19160-7
- A systematic approach to why some color scales are better than others.
https://exts.ggplot2.tidyverse.org/gallery/
- An overview of {ggplot2} extensions for special visualisations and solutions for publication-ready graphs.
Machine learning
Bradley Boehmke and Brandon Greenwell: “Hands-On Machine Learning with R”, https://bradleyboehmke.github.io/HOML/
- A great entry point for machine learning in R. It demonstrates concepts and a range of algorithms of varying complexity - from linear regression to Random Forest - with examples in R. This book served as an inspiration and starting point for the (in some ways reduced) contents of this course, covered in Chapters Chapter 9 - Chapter 12.
Pichler, M., & Hartig, F. (2023). Machine learning and deep learning—A review for ecologists. Methods in Ecology and Evolution, 00, 1– 23. https://doi.org/10.1111/2041-210X.14061
- A review paper that provides an instructive overview of machine learning and deep learning for a general readership (not just scientists in Ecology and Evolution). The paper explains also the fundamental assumptions of different methodological approaches and provides an intuitive understanding of the sometimes surprising power of machine learning algorithms.
Chollet & Allaire “Deep learning with R”, Manning Publications, Accessed February 17, 2023. https://www.manning.com/books/deep-learning-with-r.
- This is the next step after you’ve studied Applied Geodata Science I. It introduces machine learning with deep neural networks using the {keras} machine learning library (with its wrapper in R).